櫻木真乃さんと会話する
この記事は創作+機械学習 Advent Calendar 2021の 12/03 の記事です。

また、本記事・システムで使用している著作物の著作権および商標権、その他知的財産権は、当該コンテンツの提供元に帰属します。

はじめに
まずはじめに、今回紹介するシステムを以下に示します。
一言でいうと、櫻木真乃さんと会話を試みました。
システムの概要
今回のシステムは、簡単にまとめると以下の図の様になっています。
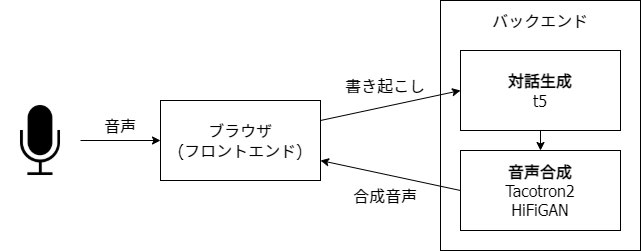
自分はネイティブアプリよりも、Web フロントエンドの方が慣れていたので、Web フロントエンド + バックエンドサーバーの形で実装しました。
フロントエンドでは
- 音声の書き起こし
- ウィンドウの制御
- アニメーションの制御
を行い、バックエンドでは
- 対話の生成
- 音声の生成
を行っています。
実際のデータの流れに合わせて、詳細を 1 つづつ説明していきます。
フロントエンド(音声の書き起こし)
対話なので、当然こちらも話すことで入力を行いたい気持ちがあります。
そのための手段としてはやはり音声認識になります。
音声認識の仕組みについて軽く説明すると、まず人間の音声データから音声区間の検出などを行い、音響モデルに入力して音素などを出力します。更に得られた音素列に近い並びの日本語の単語へとパターンマッチし、言語モデルを用いて複数の単語列から文章を構成して、書き起こし文を得ます。
最近では、この音響モデルやパターンマッチ・言語モデルなどを 1 つのモデルを行う End-to-End モデルと呼ばれるものも提案されています。音声認識や End-to-End 音声認識で参考になりそうな記事を以下に示しておきます。


音声認識のモデルを利用することも考えましたが、上記のようにかなり考える必要のあることが多いです。学習済みモデルやフレームワークを使えば楽ですが、それならもう既存の API を使うことにしました。
そのため、今回はWeb Speech APIを用いることで、フロントエンドで音声の取得・音声認識・書き下しを行ってもらいます。ありがとう Google。
フロントエンドの実装には React を用いているので、以下のライブラリを用い、Web Speech API を hooks の形式で利用しました。
これで音声を入力することで音声の書き起こし文が得られるので、得られた書き起こし文をバックエンド側に送信します。
バックエンド(対話の生成)
送られてきた書き起こし文から、対話を生成します。
当初は、エアフレンドという会話 AI を提供するサービスがあるため、櫻木真乃さんを再現した AI を対話生成部分に使う予定でした。
エアフレンドは現在 LINE 上でのみサービスが提供されているため、今回のシステムに組み込むためにはどうにかして LINE でトークを送信・取得する必要があります。LINE でトークを送信・取得するには Messaging API を用いた bot を利用することになりますが、同じトークルームに bot は 2 つ以上存在できないという仕様から、エアフレンドへの応答・対話取得は行なえません。
そのため、今回はこの部分もモデルを学習し、手元で動かすことにしました。
今回はいわゆる雑談の対話なので、非タスク指向型対話システムとなります。
非タスク指向型対話システムの方式としてはルールベースや用例ベースがありますが、ここでも深層ニューラルネットワークに直接文を入力して対話を出力させる End-to-End の方式が存在します。
現在、自然言語処理では膨大なコーパスを用いて事前学習したモデルを、翻訳や対話、分類などに転移学習するのが一般的です。今回もその流れに従い、T5と呼ばれるモデルの日本語での事前学習済みモデルを用いて、対話モデルへと転移学習しました。
今回は以下の記事で紹介されている日本語での事前学習済みモデルを用いさせて頂きました。この場を借りて御礼申し上げます。

対話への転移学習用いる学習データとして、櫻木真乃さんの会話データを用いたいところでしたが、納期や課題が襲ってくるため、友人のツイート・リプライをもとにした会話データを用いました。
つまり、実は今回のシステムは櫻木真乃さんの声で喋る友人と対話するシステムです。地獄か?
以下に学習したモデルの対話の生成例を示します。
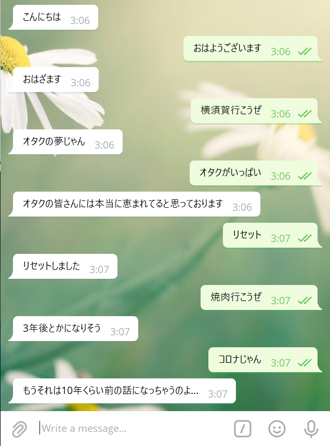
これで書き起こし文から対話が生成できるため、次に生成された文章から音声を合成します。
バックエンド(対話の生成)
現在の音声合成は、テキストからメルスペクトログラムを生成するモデルとメルスペクトログラムから音声波形を生成するボコーダーを用いるという 2 段階に分けて生成する方式が主流です。今回もこの方式に則り音声を合成しています。
まず、テキストからメルスペクトログラムを生成するモデルについて書きます。この部分には Transformer TTS、FastSpeech2 など様々なモデルが提案されていますが、今回は Tacotron2 を用いました。音声の書き起こしだけあれば学習することができ(他のモデルでは、n 秒から m 秒がこの音素という情報が必要なモデルも存在する)、比較的少なめのデータ量で学習できるため、何だかんだ使いやすいです。
しかし、それでも音声データと音声の書き起こしは必要なため、集める必要があります。今回はゲーム内の音声を直で録音し、以下のようなアノテーションツールを作って 1 文 1 文吟味しながら書き起こしました。
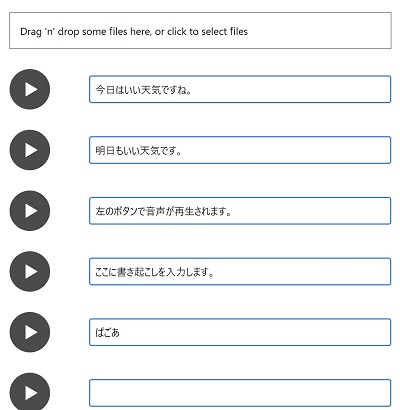
感情のこもった音声や「!」が付きそうな音声などはデータ量が少ないときは品質が下がる原因となるため、1 文 1 文吟味しました。しかし、声優さんは演技が上手いため、声によく感情がこもっており、15 分収録して使えそうな音声は 10 秒ほどだったときは頭がおかしくなりそうでした。
こうして苦労して得られた櫻木真乃さんの音声データと書き起こしですが、せいぜい総再生時間で 10 分程度です。この少ないデータ量でいかに学習させるかという課題が出てきます。先程の自然言語処理や他の機械学習と同様に、音声合成でも転移学習は有効です。そのため、今回はJVS コーパスと公開されている音声データを用いて Tacotron2 を学習してから、集めた音声データを用いて転移学習を行いました。
次に、ボコーダー部分について書きます。
ボコーダーに深層ニューラルネットワークを用いたニューラルボコーダーと呼ばれるものが高品質なためよく用いられます。
今回は対話なので推論速度も欲しいため、GAN ベースのニューラルボコーダーであるHiFiGANを用いました。WaveNet や WaveRNN の自己回帰モデルはやはり品質が高いのですが、生成速度は GAN ベースのものに劣るという印象です。
学習データにはJVS コーパスと集めた音声データを用いて、話者非依存(モデルに話者ラベルを与えない)形式で学習を行いました。
以下に音声の生成例を示します。
やはり 10 分と非常に学習データが少ないのと、声質が特徴的なため、同じ条件の JVS の話者の合成音声よりも劣っている感があります。
まあ声質が特徴的だからこそ櫻木真乃さんを選んだので後悔はないです。
これで対話文から音声データを生成できたので、base64 エンコードすることで文字列として音声ファイルを扱えるので、フロントエンド側に json に詰めて返します。
フロントエンド(ウィンドウの制御・アニメーションの制御)
バックエンドから送られてきた音声データは、javascript で以下のように再生ができます。
const dataURL = "data:audio/wav;base64," + base64Wav;
const sound = new Audio(dataURL);
sound.play();
sound.addEventListener('ended')やsound.addEventListener('play')で音声データの再生に合わせて、ウィンドウやアニメーションを制御します。
ここまでアニメーションと書いていますが、さすがに Live2d や Spine で 2d アニメーションさせる能力はないため、ゲームを直撮りし、待機中用・話はじめ用・話し中用の 3 つのビデオにいい感じに編集しています。
再生が開始されると、対話文をウィンドウに表示し、ループしていた待機中用のビデオが話はじめのビデオに切り替わります。
話はじめのビデオが終了すると、話し中用のビデオが自動的にループするようになっています。音声データの再生が終了すると、ウィンドウが消え、待機中用のビデオのループに戻ります。
以上で紹介したものを一緒に動かすと、冒頭で紹介した動画のようなシステムとなります。
future works
今後の課題として、合成音声の品質の改善、対話文の感情認識と感情のこもった音声の合成、感情に合わせたアニメーションの制御などが挙げられます。
合成音声の品質の改善はデータ量を増やすだけなので気合ですね。感情のこもった音声の合成もデータ量の増強と感情ラベルのアノテーションに帰着します。いきなり感情は難しいので、まずは極性判定をもとにして音声を合成してみるなどもありかもしれません。
感情に合わせたアニメーションの制御は、さすがに 3d モデルやアニメーターさんにアニメーションを作ってもらうなどを視野に入れないと厳しそうです。今回はせいぜい 3 つの動画のコントロールですが、表情まで管理するとなると React くんがたぶん過労死します。
まとめ
今回は、基本的に公開されているデータと、個人で手に入る範囲のデータのみで、キャラクターと会話することができることを示せたと思います。計算機だけは大学のを使いましたが、計算機は AWS や GCP でどうにでもなると思います。ここ 3 年ほどで、エアフレンドなどのサービスや音声合成サービスなどが急速に出てきている印象なので、今後は 1 枚の学習データと 10 秒の音声データさえ用意すれば会話できる時代が近づいているのかもしれません。
今回のシステムはさすがにモノがモノ(著作権 etc.)なので、公開予定はありません。(あと GPU 代で普通に破産すると思う。)
また、今回用いたモデルのコードは、自分が実装した Tacotron2 などを利用したため、特に公開予定はありません。ESPNetなど、日本語の事前学習済みモデルを動かす・学習させるツールキットがあるので、むしろそちらを使うほうがもっといい品質で出来ると思います。
記事で書ききれていないことや、疑問などがありましたら、Twitterなどで問い合わせていただければ、なるべく答えるように努力します。(論文の締切がそろそろあるため...)
今回創作+機械学習 Advent Calendar 2021 には飛び入り参加しましたが、12/03 の記事ということになっているので、
前日の記事は amane_lyric さんのそのキャラを好きになった理由を探る、
翌日の記事は wakadori さんの機械学習でイラスト生成しようと思ってたらいつのまにか自分で生成することになってた話
です。どちらも面白い記事で、モデルを学習中に読ませて頂きました。
創作+機械学習 Advent Calendar 2021 の CFPでは、友利奈緒の声を求めてなどが例に出されていたので、そのノリのタイトルにしたら思ったよりちゃんとしたタイトルが多く、ビビリ散らかしています。
最後に、今回これを制作するきっかけとなった創作+機械学習 Advent Calendar 2021の企画者の皆さん、ツイートデータを使わせてくれた友人、読んでくれた皆さんにこの場を借りてお礼申し上げます。